In the first article of this three-part series on fail-safe design, we have spent some time discussing how unexpected failures can threaten the integrity of an application by corrupting both the application data and file system metadata.
This time, we look at how an application can be designed to withstand such unforeseen events using an embedded fail-safe file system such as TSFS. TSFS being a transactional file system, the user has access to a powerful tool in the form of transactions to enable atomic updates of important files. Doing so, we introduce the tsfs_commit() API. We also discuss the write transaction atomicity property, by which applications can be safely designed ignoring potential partial update issues.
What are TSFS Transactions?
TSFS supports both read and write transactions. Since read transactions have more to do with concurrent access management than with fail-safe design, we will save those for another article. For now, let’s focus on write transactions.
A TSFS write transaction is a sequence of write operations that either succeeds or fails as a whole. Partial operations (or sequences of operations) can never happen, and thus, only one of two possible outcomes can be observed:
- the transaction completes without interruption and the file system state reflects the result of the entire sequence of write operations.
- a failure occurs during the transaction and the file system is returned to its initial state (i.e. the one it was in when the transaction started).
This all-or-nothing behaviour is guaranteed by the write transaction atomicity property. In TSFS, this property applies equally to data and metadata updates.
A Simple Transaction Usage Example
A transaction is ended using tsfs_commit(). A new transaction is automatically started each time a transaction is ended. The very first transaction is started upon mounting.
Recalling our certificate update example of the previous article, let’s see how it works. The following code listing uses the same pseudocode as the previous article, with one major difference: calls to tsfs_commit() have been added before and after the write loop. Consequently, all the write operations within the loop are part of a single transaction.
// Open a connection to the server.
c = net_open(srv_addr, cert_path);
// Open the file containing the certificate.
rtn = tsfs_file_open("fs0/cert.crt", &fh);
if (rtn != RTNC_SUCCESS) { /* Error handling. */}
// Send the certificate request to the server.
net_send(c, cert_req_str, sizeof(cert_req_str));
// End the previous transaction and start a new one.
rtn = tsfs_commit("f0");
if (rtn != RTNC_SUCCESS) { /* Error handling. */}
do {
// Fetch the next chunk of certificate from the server.
net_recv(c, p_buf, buf_sz, &rx_sz);
// Write to the fetch chunk to the certificate file.
rtn = tsfs_file_write(f, p_buf, rx_sz, &sz);
if (rtn != RTNC_SUCCESS) { /* Error handling. */}
} while (rx_sz > 0u);
// End the previous transaction and start a new one.
rtn = tsfs_commit("f0");
if (rtn != RTNC_SUCCESS) { /* Error handling. */}
// Close the server connection.
net_close(c);
// Close the certificate file.
rtn = tsfs_file_close(f);
if (rtn != RTNC_SUCCESS) { /* Error handling. */}
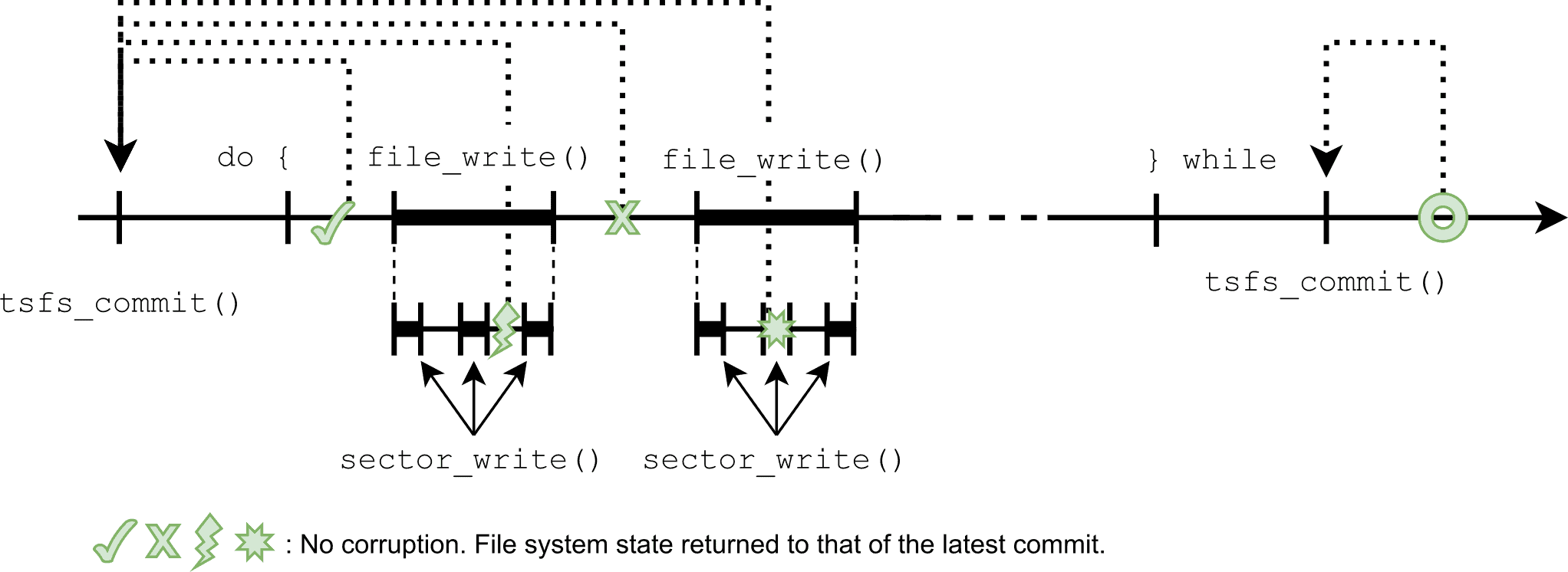
Now, consider the various failure scenarios shown in Figure 1 — respectively represented by a check mark, a lightning bolt, an ‘X’, a star and a circle. In the previous article, we have seen how these failures could lead to data and/or metadata corruption. Using transactions, this is no longer the case.
Since all the file write operations are now part of a single transaction, they either succeed or fail as a whole, leaving no room for half-complete updates. No matter how and when it fails, the file system is always returned to the state it was in at the time of the latest commit. This is represented by the dotted arrows in the following diagram.
Since the transaction atomicity property applies equally to application data and file system metadata, both are protected against corruption.
The Recovery Procedure
The details of the recovery procedure following an unexpected failure depends on the application, as well as the nature of the failure. But as far as TSFS is concerned, it all boils down to one of the following scenarios:
- The failure is serious enough that the device is (or has to) shut down. It could be a sudden power loss. Or it could be some critical system error requiring an immediate reset. In both cases, the state of the file system as of the latest commit is restored upon rebooting, more specifically, upon mounting the file system using
tsfs_mount(). - the failure does not require a reset. In our small application example, this could be some network failure requiring a new certificate download attempt. In this case, the latest consistent state can be programmatically restored using
tsfs_drop(). This situation is shown in Figure 2.

In both cases, the time it takes for the recovery to complete is short. Most importantly, it is independent of the number of uncommitted operations accumulated between the latest commit and the failure. This is unlike journaled file systems, which must often perform a large number of reverse operations at mount time in order to revert to a known consistent state.
Conclusion
In this second out of three articles on fail-safe design, we have discussed the use of TSFS write transactions as a means to recover from unexpected failures.
We have shown how tsfs_commit() can be used to group several write operations into a monolithic write transaction. We have then introduced the write transaction atomicity property and shown how this particular property translates into consistent application-level behaviour, independent of possible random failures. Finally, we have discussed possible recovery scenarios and explained how TSFS transactional behaviour accounts for shorter recovery times than journaled file systems.
In the next article of this series, we will see how TSFS transactions go beyond protecting against corruption and simplifies application design by enabling data coherence across entire data sets, possibly containing thousands of files and directories.
Click here to read the next part of this article series discussing file coherence.
Questions or comments?
Do not hesitate to contact us at blog@jblopen.com. Your questions, comments and, suggestions are appreciated.