This is the first article of a three-part series on fail-safe, storage-related application design using an embedded file system. The first part of the series lays out the fundamental problem of unexpected failures and briefly discusses partial solutions. The second part introduces how a fail-safe transactional file system such as the TREEspan File System (TSFS) can be used as a mean to protect the application against such potentially disruptive events. Finally, the third part, discusses how TSFS transactions extend beyond the simple protection against local corruption, by providing strict coherence guarantees across multiple files and directories.
To better understand how unexpected failures can translate into application-level problems, let’s consider a small edge device requiring a public-key certificate to securely communicate with a central server. As security is not the focus of this article, we purposely ignore important security aspects to focus on the following:
- The certificate is stored as a single file on some non-volatile media (e.g. NOR flash).
- The edge device cannot communicate with the server without a valid certificate.
- The edge device must fetch a new certificate from the server at regular intervals.
We are particularly interested in the certificate update process. The pseudocode for a straightforward implementation is given in Listing 1. If everything goes as expected, the old certificate is overwritten by the new one and the next time a connection is established the new certificate is used. But what if some random failure — be it the result of a power loss, bus error or inadvertent user action — occurs halfway through?
// Open a connection to the server.
c = net_open(srv_addr, cert_path);
// Open the file containing the certificate.
f = file_open(cert_path);
// Send the certificate request to the server.
net_send(c, cert_req_str, sizeof(cert_req_str));
do {
// Fetch the next chunk of certificate from the server.
net_recv(c, p_buf, buf_sz, &rx_sz);
// Write to the fetch chunk to the certificate file.
file_write(f, p_buf, rx_sz);
} while (rx_sz > 0u);
// Close the server connection.
net_close(c);
// Close the certificate file.
file_close(f);
The Problem
Unexpected failures can lead to both data and metadata corruption. Data (as opposed to metadata) refers to the data provided and retrieved by the application. Metadata, on the other hand, refers to the file system’s internal, on-disk structures.
When data corruption occurs, the file system can still operate normally. Only those modules whose files have been corrupted are jeopardized. The rest of the application can still run normally. This is unlike metadata corruption which can trigger unrecoverable errors with disastrous consequences for the entire application.
Whether metadata or data corruption occurs depends on (among other things) the timing. Recalling our certificate update application example (see Listing 1), let’s examine various timing scenarios.
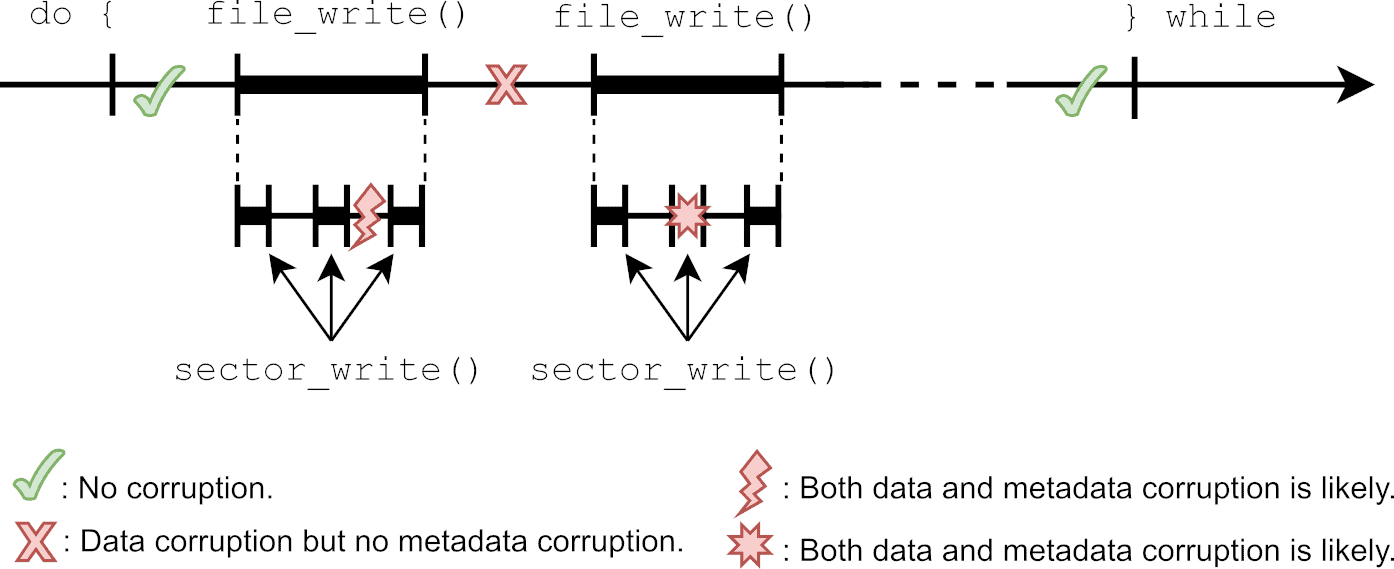
First, consider the two failures represented by green check marks on the timeline of Figure 1. As both failures happen respectively before and after the update procedure, both the data and metadata are either untouched or fully updated. Therefore, nothing is corrupted.
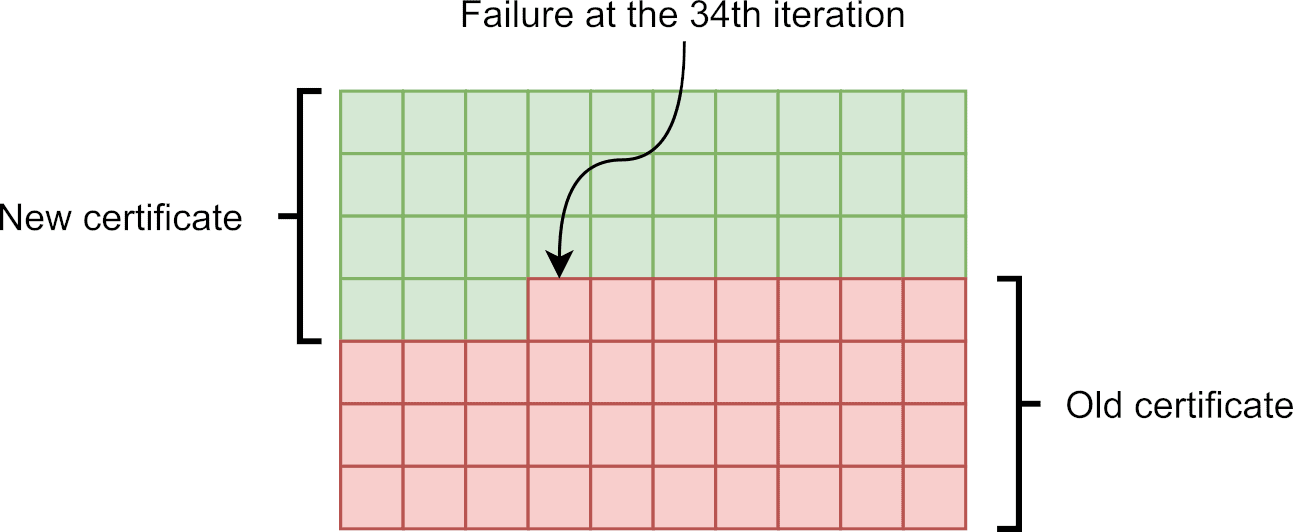
Next, consider the failure represented by a red ’X’. Since the failure happens midway through the update procedure, the file is only partially updated. Such a data corruption is depicted in Figure 2. As for the metadata, when the first file_write() completes, the file system is returned to a consistent state. Therefore, the metadata is safe. The overall outcome is nonetheless disastrous for the application as the new certificate is incomplete and the old one is lost. The device can thus no longer connect to the server, possibly compromising the whole application.
Now, consider the failure represented by a red lightning bolt. In this case, data corruption is still probable. Furthermore, since the failure happens during a call to file_write(), metadata updates may be incomplete. In a FAT file system, for instance, the failure could occur between the cluster allocation and linking steps. Since these are potentially made of two different sector updates, this specific timing could yield inconsistent allocation table entries. This corruption of the allocation table could, in turn, translate into storage leakage, or even nastier types of corruption such as cross-linking (i.e. two files sharing the same cluster), depending on the actual FAT implementation.
Finally, consider the failure represented by a red star. This scenario is similar to the previous one in that both data corruption and metadata corruption are possible. But in this case, since the physical sector update itself is interrupted, the actual outcome depends on the underlying media. Some media feature atomic updates, in which case a sector is guaranteed to be either untouched or fully updated (but never in between). Others, guarantee in-order updates, where a contiguous portion of the sector is updated, the rest being left untouched. Still others, offer no guarantee at all, and the updated sector can end up in pretty much any random state.
A Partial Solution: Application-Level Recovery
Going back to our small application example, one could protect against data corruption by writing the new certificate out-of-place (as opposed to overwriting the old one), and delete the old certificate only when the new one has been fully written. Some kind of checksum could be used to make sure that the new certificate is valid. After an untimely interruption, the application could recover using the old certificate to start over the certificate update procedure if needed.
While this approach makes sense when a whole file is updated at once (as is the case in our small example), it does not help for small write accesses, unless you can tolerate the (potentially extreme) overhead of copying the whole file each time it is modified.
Also, recovering from data corruption at the application level, requires that the metadata remain uncorrupted. Which leads us to the next partial solution: journaling.
Another Partial Solution: Journaling
Several file systems use a mechanism known as journaling to better cope with unexpected failures. In the embedded world, a popular solution is FAT with an added journal. But regardless of the implementation, the purpose of journaling remains the same: protecting against metadata corruption by either rolling back or completing partial updates upon recovery.
With a few (performance-hogging) exceptions, journaled file systems offer no additional protection for application data. Besides, most journal implementations rely on atomic sector updates, which, as we have seen, is not guaranteed for all media.
Finally, journaling is generally not compatible with write-back caching or, at the very least, hampers write-caching performances as it requires strict sector write ordering.
Conclusion
In this first article of a threefold series on fail-safe design, we have shown that unexpected failures can be harmful to both the application data and file system metadata. We have discussed how the nature and severity of the corruption depend largely on timing.
Two possible approaches to fail-safe design, application-level recovery (for data protection) and journaling (for metadata protection), have been considered. Although, taken together, these solutions go some way toward protecting against unexpected failures, we have seen that they also suffer important limitations: inadequacy for common application designs, added application-level complexity, performance loss, assumption of uncertain media behaviour.
In the next article of this series, we will introduce TSFS transactions as a means to recover from untimely interruptions, protecting both the data and metadata. We will see that, using TSFS transactions, fail-safe design can be achieved with very few additional application code and minimal performance overhead.
Click here to read the next article in this series covering TSFS transactions.
Questions or comments?
Do not hesitate to contact us at blog@jblopen.com. Your questions, comments and, suggestions are appreciated.