In this article, I’ll explore the interrupt latency, also known as interrupt response time, of an ARM Cortex-A9 under various scenarios — and yes, it’s still on the Xilinx Zynq-7000, since I still have that board on my desk from the last two articles. An upcoming follow-up article will describe methods of improving worst case latency.
Embedded Systems and Application Processors
With the ever-increasing requirements of modern embedded applications, it’s not surprising that more and more device designs are making the jump from smaller embedded chips to more powerful application class processors. And this isn’t very surprising — even their names could have helped anyone foretell this trend. MCUs, or microcontrollers, are designed to perform control tasks, while microprocessors, on the other hand, are more suited for processing data. Modern applications are all about data.
Often the first question that arises, when starting or migrating a design to an application processor, is about interrupt latency. Interrupt response time is often stated as a simple number, which at the end of the day doesn’t mean much. If I wanted to give a sales pitch, I could say that I can get you to the first instruction of your ISR in less than a 100 cycles, which on your typical MPU would be less than 200 ns. That’s right, nanoseconds. But that doesn’t mean much, because if an application is latency-sensitive, that’s just about the worst case scenario. Worst-case interrupt response time is application-dependent, with a mix of variables affecting the results, including memory type, CPU configuration, and application behaviour.
Interrupt Latency on the Cortex-A
Interrupt latency is mostly affected by how much time it takes for the CPU to fetch the necessary instructions and data in order to process the interrupt entry sequence. On a higher-end platform, this is complicated by the more complex memory hierarchy and memory management. For example, in a Cortex-M, an instruction or data fetch can be done in a well-bounded amount of time, while a Cortex-A requires many more steps when fetching from memory.
Getting an instruction or data will first require a TLB lookup, which may require a page table walk, and which may or may not be cached. And at this point, the access itself hasn’t been done. A memory access must cross the entire memory hierarchy in search of either a cache hit or the underlying memory. Most modern Cortex-A processors are implemented with a 4-level memory hierarchy. The L1 and L2 cache are usually named as such, while the central interconnect would be L3 and external memory located at L4.
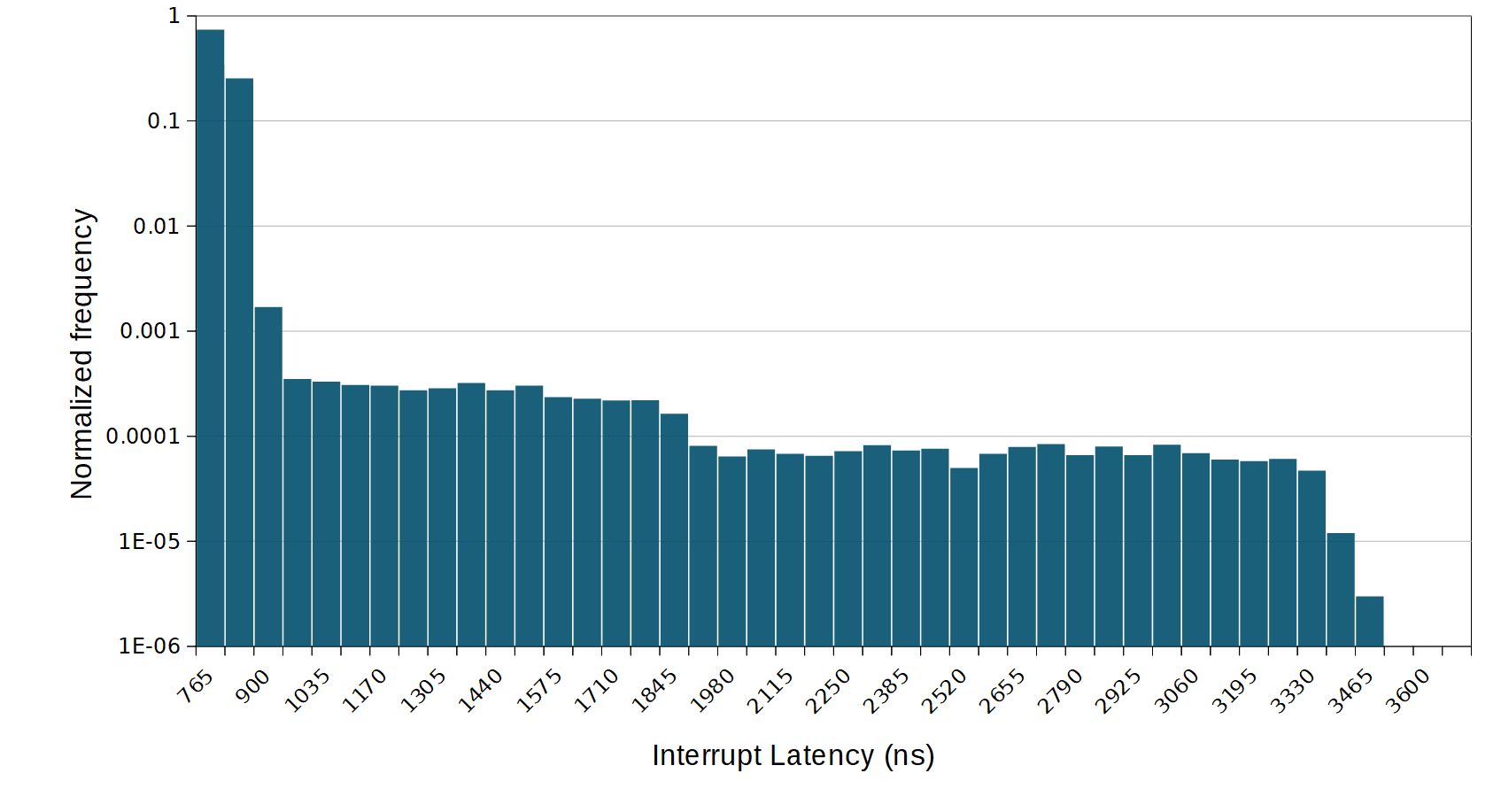
Rather than belabouring the point with a long theoretical discussion, I’ve simply measured interrupt latency under a few configurations with varying cache states. Measurements were done by using a software-generated interrupt on a Zynq-7000 running at 667Mhz. The values are quoted in CPU cycles, and includes the measurement and interrupt generation overhead.
The table contains measurements for four different configurations. Two of those configurations feature code and data stored in external DDR memory, and two with code and data in the on-chip RAM (OCRAM). Both configurations were tested with memory marked as cacheable and non-cacheable.
| Configuration | Scenario | Min | Max | Avg |
|---|---|---|---|---|
| DDR Cached | Normal | 242 | 242 | 242 |
| DDR Cached | TLB Invalidate | 326 | 496 | 328 |
| DDR Cached | BP Invalidate | 298 | 298 | 298 |
| DDR Cached | TLB+BP Invalidate | 384 | 478 | 396 |
| DDR Cached | L1I Clean | 400 | 414 | 404 |
| DDR Cached | L1D Clean | 396 | 420 | 408 |
| DDR Cached | L1 D+I Clean | 532 | 580 | 546 |
| DDR Cached | L2 Clean | 242 | 242 | 242 |
| DDR Cached | L1+L2 Clean | 1582 | 2978 | 1844 |
| DDR Cached | L1+L2+BP+TLB Clean | 1746 | 2896 | 1892 |
| OCRAM Cached | Normal | 240 | 240 | 240 |
| OCRAM Cached | TLB Invalidate | 242 | 242 | 242 |
| OCRAM Cached | BP Invalidate | 298 | 298 | 298 |
| OCRAM Cached | TLB+BP Invalidate | 298 | 298 | 298 |
| OCRAM Cached | L1I Clean | 402 | 424 | 410 |
| OCRAM Cached | L1D Clean | 424 | 462 | 448 |
| OCRAM Cached | L1 D+I Clean | 588 | 620 | 600 |
| OCRAM Cached | L2 Clean | 240 | 240 | 240 |
| OCRAM Cached | L1+L2 Clean | 592 | 620 | 594 |
| OCRAM Cached | L1+L2+BP+TLB Clean | 580 | 626 | 596 |
| DDR Uncached | Normal | 2076 | 3182 | 2186 |
| DDR Uncached | TLB Invalidate | 2100 | 3204 | 2210 |
| DDR Uncached | BP Invalidate | 2846 | 4010 | 2984 |
| DDR Uncached | TLB+BP Invalidate | 2874 | 4052 | 2996 |
| DDR Uncached | L1I Clean | 2818 | 4062 | 2980 |
| DDR Uncached | L1I+BP+TLB Clean | 2880 | 3996 | 2986 |
| OCRAM Uncached | Normal | 686 | 700 | 690 |
| OCRAM Uncached | TLB Invalidate | 692 | 694 | 692 |
| OCRAM Uncached | BP Invalidate | 822 | 822 | 822 |
| OCRAM Uncached | TLB+BP Invalidate | 822 | 822 | 822 |
| OCRAM Uncached | L1I Clean | 822 | 822 | 822 |
| OCRAM Uncached | L1I+BP+TLB Clean | 822 | 822 | 822 |
Analysis
Let’s look first at the normal configuration, which would be code and data stored in cached external DDR. The best case interrupt latency is 242 cycles, which for a 667 Mhz Zynq is about 0.36 µs — not bad. Worst case in the measured scenarios is with a clean L1 and L2 caches, as well as empty TLB and branch predictors. In that later case, measurements show a worst case of 3996 cycles or nearly 6 µs. Moving code and data into on-chip memory gives a very similar best-case; this makes sense, since this is with a warm L1 cache, so memory access never reaches L2. The worst case is improved to 626 cycles/0.9 µs. A point of note is that on the Zynq, the OCRAM is located at the same level as the L2 cache, so access to the OCRAM from the CPU do not have to cross the central interconnect.
There are also a few oddities that might seem strange at first. One of them is the impact of a cold TLB, which doesn’t count for much, or in some cases at all, if we trust the measurements. For example, when running from on-chip RAM. clearing the TLB seems to have no effect. This is mostly because the code and data fit in a full page, as such only one fetch is required from the page table. In those cases, even if the TLB is flushed before measuring, the access is done prior to the measurement, and isn’t captured in the data. The memory layout for the configuration in external memory is a little different, and requires two table lookups instead of one.
Parting Words
The measurements, however, do not reflect the absolute worst case scenario, as we are considering clean caches with a mostly idle SoC. It’s important when qualifying a design for worst-cast interrupt response time to use the complete application. If possible, I’ll try to simulate a mostly dirty cache with some interconnect contention before the next post, which will be about how to mitigate interrupt latency in a Cortex-A based system.
Click here to read the follow-up article on how to improve the interrupt latency on a Cortex-A9.
Questions or comments?
Do not hesitate to contact us at blog@jblopen.com. Your questions, comments and, suggestions are appreciated.